Overview
This is a short overview about the Bachelor’s thesis I wrote about “Composing a melody with long-short term memory (LSTM) Recurrent Neural Networks” at the Chair for Data Processing at the Technical University Munich. For a more in-depth understanding of the topic you can read the whole thesis following the link. The code that has been used to implement the LSTM Recurrent Neural Network can be found in my Github repository. Most interestingly are probably the listening examples of the Neural Network Compositions, which can be found further below. Furthermore, the evaluation of the composed melodies plays an important role, in order to objectively asses the quality of the LSTM RNN composer and therefore be able to make a contribution to the research in this area.
Goal
The goal of this thesis was to implement a LSTM Recurrent Neural Network (LSTM RNN) that composes a melody to a given chord sequence. The compositional aims are that the melody sounds pleasantly to the listener and cannot be distinguished from human compositions. These two aims have been evaluated in a listening test with human subjects, which is further explained in the evaluation section.
Implementation
For the training of the LSTM RNN chord/melody pairs of Beatles songs have been used, where the chords feed-forward through the network and the belonging melodies are the target values. So to say, the LSTM RNN learns which melodies fit to certain chord sequences and once a new chord sequence is presented to the network it should be able to predict which melody fits to this chord sequence.
The training data consists of 68 different chord/melody pairs taken from 16 different Beatles songs. The chord/melody pairs have been created in MIDI format and are transformed into a piano roll matrix, consisting of ones if a note is “on” and zeroes if a note is “off”. The transformation process is more detailed in the thesis.
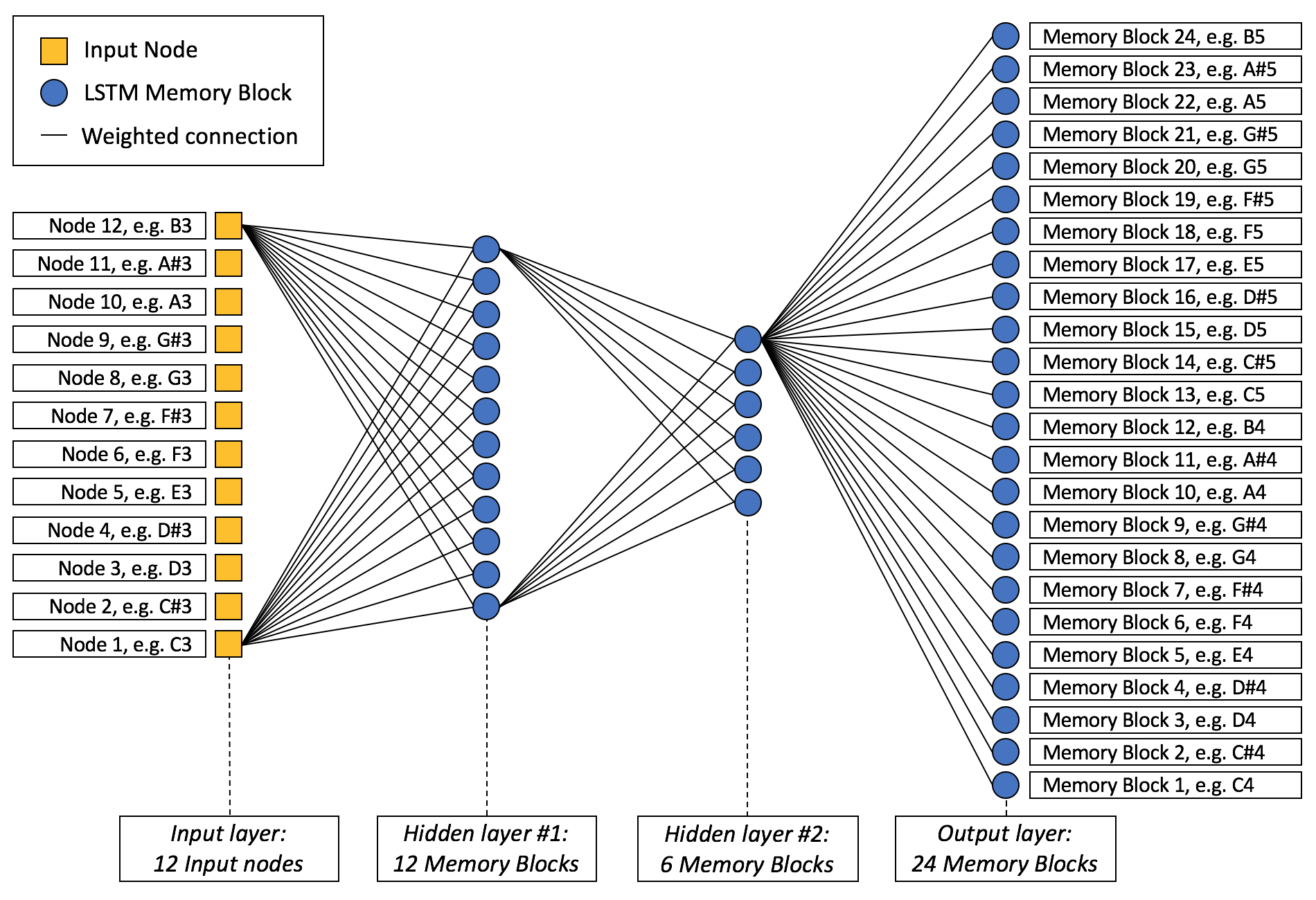
In order to reduce the computational costs, the LSTM RNN’s architecture has been restricted to twelve input nodes and 24 output nodes. Each node represents one pitch, meaning that chords that will feed-forward through the network need to be in the pitch range of an octave. The same goes for the melodies, which are available to the network at the output layer, thus need to be in the pitch range of two octaves. The number of hidden layers and nodes per hidden layer has been varied while conducting the experiments. For more detailed information, see the “Experiments” section of the thesis.
Listening Examples
After conducting the experiments with several different Network architectures, a network with two hidden layers (9 nodes in the first hidden layer, 18 nodes in the second one) has been chosen as the most promising architecture to fulfill the compositional aims from above.
Eight different chord sequences have been used to which the LSTM RNN composed the melodies. In addition, humans were asked to compose melodies to the same chord sequences in order to be able to evaluate the computer compositions. In the following you can listen to the chord sequences, the computer compositions as well as the human compositions. It should be noted, that all compositions have been made in MIDI format, while a simple piano VST-instrument has been used as the sound engine.
| Chords only | Computer compositions | Human compositions | |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 |
Evaluation
In order to be able to evaluate the compositional aims (1. The Melodies should sound pleasantly; 2. The melodies should be indistinguishable from human melodies) an online listening test with 109 human subjects has been conducted. The listening test has been divided into two parts.
Part One
The first part aims to evaluate whether the computer melodies sound pleasantly to the listener. The subjects were presented the computer composition as well as the human composition for each chord sequence and they were asked to indicate, which melody they like better. During the first part, the subjects haven’t been told, that some melodies have been composed by a computer.
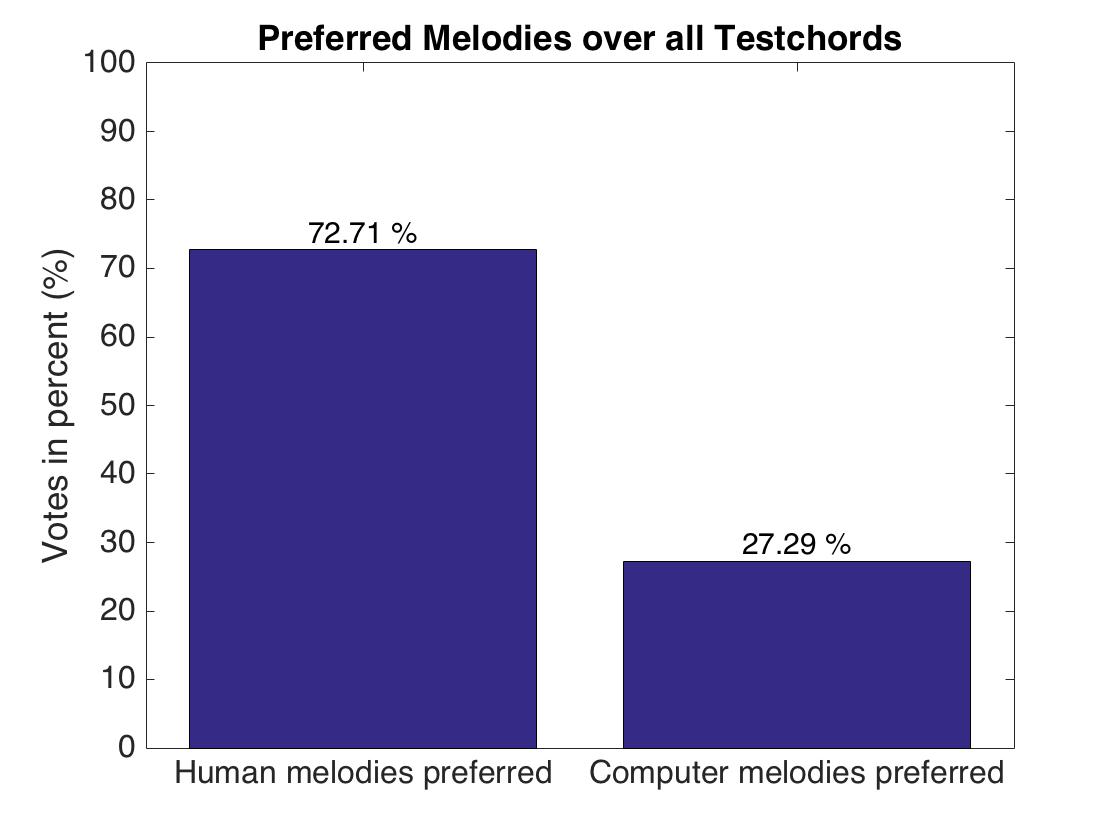
In about 73% of the cases the human melody was preferred over the computer composition, which indicates a clear preference for human melodies. Thus one can suggest that human melodies sound more pleasantly to the listener than the computer melodies. However, in more than one-fourth of the cases the subjects preferred the computer composition, which shows that a few computer melodies did sound indeed more pleasantly than the human compositions.
Part Two
The second part aims to evaluate whether the computer melodies can be distinguished from human melodies. Here, the subjects have been told that some melodies are composed by a computer. The subjects were presented all 16 melodies after each other (8 computer melodies, 8 human melodies) and were asked for each melody, if they think it was composed by a computer or by a human.
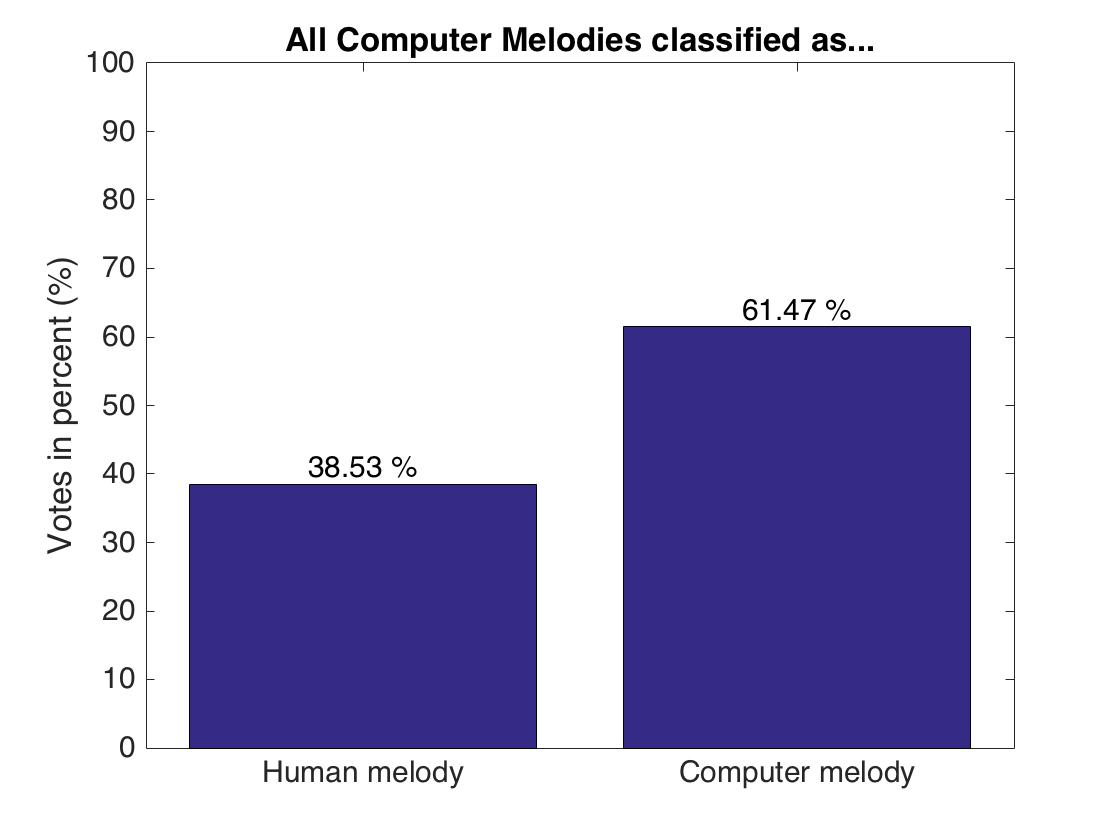
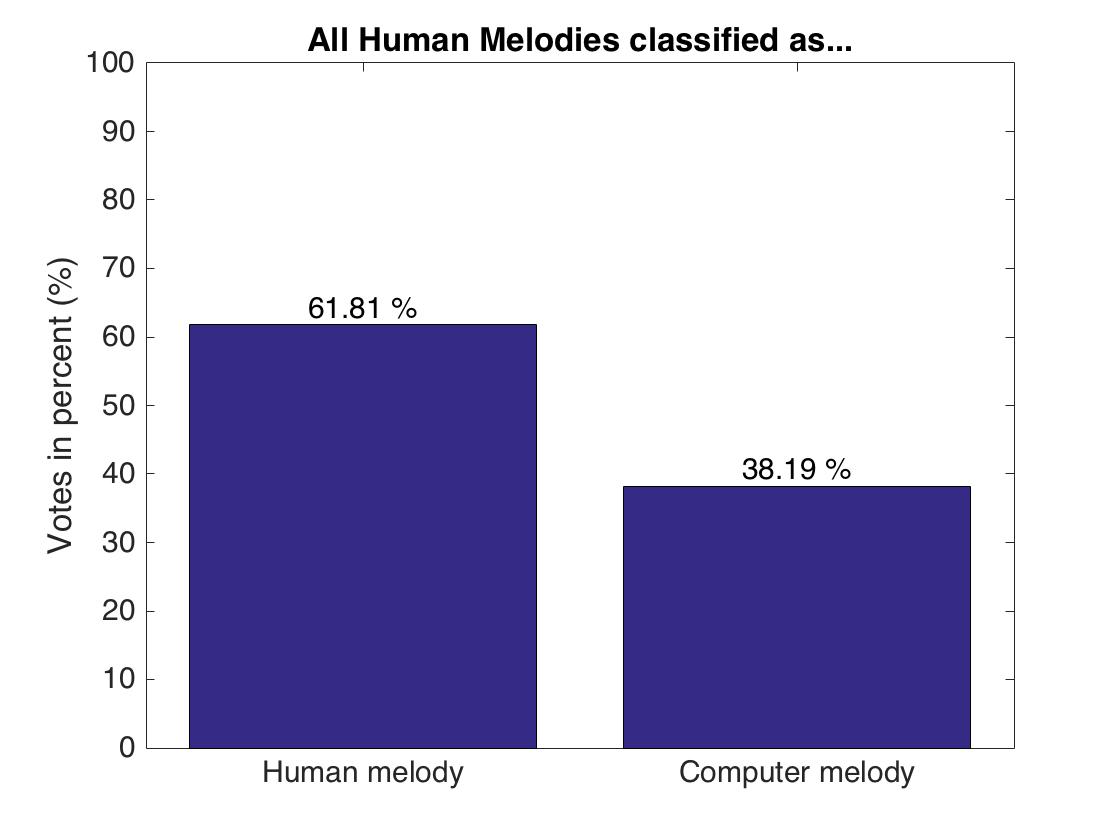
Both human and computer melodies have been correctly classified in about 61% of the cases, giving a classification accuracy of 0.6164. This means that there is a distinguishable difference between human and computer compositions, even though this is not a very distinct difference, as 40% of the computer melodies have been falsely classified as human melodies. It has to be noted that the subjects were differently biased on the expectations about a computer composition. Some subjects noted in their feedback, that they expected computer melodies to be “almost perfect”, while others assumed that a computer is generally unable to compose music.
For a more detailed explanation of the evaluation, see the “Evaluation” part of the thesis.
Conclusion
The main goal for this thesis was to implement a long-short term memory Recurrent Neural Network, that composes melodies that sound pleasantly to the listener and cannot be distinguished from human melodies. As the evaluation of the computer compositions has shown, the LSTM RNN composed melodies that partly sounded pleasantly to the listener. However, in the majority of the cases the human compositions were preferred, thus the LSTM RNN did not fully succeed in fulfilling the first requirement. In addition, the computer compositions could be recognized as such in about 60% of the cases, making them distinguishable from human compositions. Still, in 40% of the cases the computer melodies were misclassified as human melodies. Overall the LSTM RNN did not succeed in completely fulfilling the main goals for this thesis, but it did in fact compose very interesting and nice sounding melodies at parts, that satisfy those goals.
A final result is an implementation of a LSTM Recurrent Neural Network, that composes a melody to a given chord sequence, which, apart from any requirements of this thesis, can be used as a creative tool of inspiration for composers and music producers.
If you have any questions about the thesis or want to discuss further developments of algorithmic music composition, feel free to contact me via konstantinlackner@gmail.com. I always appreciate feedback.
Credits
A big thanks to:
- Thomas Volk, for supervising the thesis, the helpful and critical discussions and keeping me on track, when things didn’t want to work out in the beginning
- Prof. Diepold, for giving me the opportunity to write about the topic of Algorithmic Composition
- Douglas Eck, for sharing important insights at an early stage of the thesis
- Bernat Fages, for sharing his thesis and code, which helped a lot during the implementation phase
- To everyone who participated in the listening test. I love you all ☺
Links
Here you can find a (non-comprehensive) list with links related to the topic:
- http://people.idsia.ch/~juergen/blues/
- https://github.com/bernatfp/LSTM-Composer
- http://www.hexahedria.com/2015/08/03/composing-music-with-recurrent-neural-networks/
- http://www.brandmaier.de/alice/
- http://www.wise.io/tech/asking-rnn-and-ltsm-what-would-mozart-write
- https://highnoongmt.wordpress.com/2015/05/22/lisls-stis-recurrent-neural-networks-for-folk-music-generation/
- http://gitxiv.com/posts/WEoQCj8hxHz6vPxe6/gruv-algorithmic-music-generation-using-recurrent-neural